Transferable Contrasive Network for Generalized Zero-Shot Learning
前言
与半监督图像学习、小样本学习等领域不同的是,零样本学习开始引入一些语义信息,可以理解为同时利用图像与文本信息。在前言部分,我们从零样本学习的定义(what)、具体的用途(why)、以及实际方法(how)来简要介绍该研究领域。此外,我们详细地介绍了一篇CVPR2019广义零样本学习的代表工作。
零样本学习(zero-shot learning/ZSL)的定义
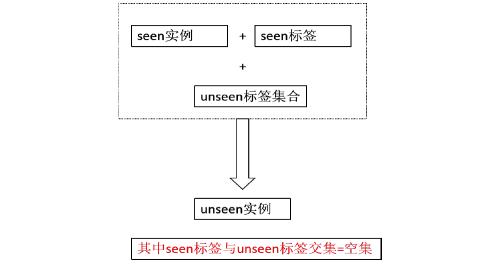 零样本学习的目的是为一个样本不可见的类别构建模型。举一个例子来说:拥有0-7的数字图像和对应标签,但是没有8, 9的样本,现在需要为8, 9去构建一个分类模型。 ### 应用 1.新类别的图像合成。ZSL的学习目标是识别新事物,一些新类别的图像合成,完全可以通过ZSL被创造出来。比如还原已经灭绝的物种。也许未来你在《侏罗纪》系列中看到的恐龙,就是机器“画”出来的。 2.多模态学习。ZSL基本上是依靠类别名称的语义来完成这种零样本的知识迁移的:虽然没有对应类别的样本,但是我们知道类别的名字,比如斑马。而斑马的词向量(可以由Bert来获取)与黑白、马等概念接近,我们就可以通过已有的马的图像来构建斑马分类器。越来越多的数据是视觉与文本信号共同出现,比如综合性视频网站,视频、音频、字幕、弹幕、评论等多模态信息都有,想要挖掘它们之间的相关性,就依赖于ZSL的宏观预测能力。 ### 如何做 本篇论文提供了一个简单直接的方式去完成这一任务,它通过语义的相似性去构建伪标签、并用多类别学习来进行ZSL。 ## Abstract ZSL需要模型识别一个没有可见样本的目标类别,它利用语义信息去迁移一些源类别的知识。目前ZSL很容易在generalized ZSL任务上对源类别过拟合。本工作提出了transferable contrasive network,它直接从源类别迁移知识到目标类别。该方法自动地对比一张图片和几个类别是否一致,达到了更鲁棒的识别性能。
零样本学习的目的是为一个样本不可见的类别构建模型。举一个例子来说:拥有0-7的数字图像和对应标签,但是没有8, 9的样本,现在需要为8, 9去构建一个分类模型。 ### 应用 1.新类别的图像合成。ZSL的学习目标是识别新事物,一些新类别的图像合成,完全可以通过ZSL被创造出来。比如还原已经灭绝的物种。也许未来你在《侏罗纪》系列中看到的恐龙,就是机器“画”出来的。 2.多模态学习。ZSL基本上是依靠类别名称的语义来完成这种零样本的知识迁移的:虽然没有对应类别的样本,但是我们知道类别的名字,比如斑马。而斑马的词向量(可以由Bert来获取)与黑白、马等概念接近,我们就可以通过已有的马的图像来构建斑马分类器。越来越多的数据是视觉与文本信号共同出现,比如综合性视频网站,视频、音频、字幕、弹幕、评论等多模态信息都有,想要挖掘它们之间的相关性,就依赖于ZSL的宏观预测能力。 ### 如何做 本篇论文提供了一个简单直接的方式去完成这一任务,它通过语义的相似性去构建伪标签、并用多类别学习来进行ZSL。 ## Abstract ZSL需要模型识别一个没有可见样本的目标类别,它利用语义信息去迁移一些源类别的知识。目前ZSL很容易在generalized ZSL任务上对源类别过拟合。本工作提出了transferable contrasive network,它直接从源类别迁移知识到目标类别。该方法自动地对比一张图片和几个类别是否一致,达到了更鲁棒的识别性能。 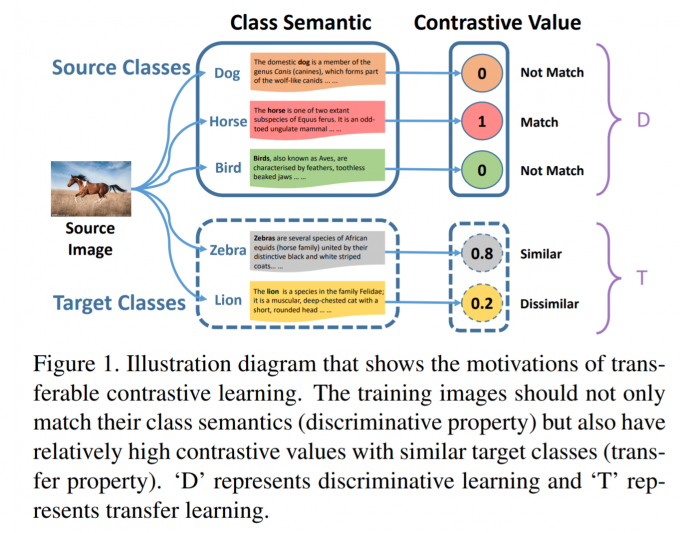
Introduction
ZSL目的是为目标类别学习一个分类器,并且不使用任何对应样本。它基本的思想是通过语义信息从源类别迁移知识。语义信息可以建立不同类别的关系,从而能够完成源类别到目标类别的知识迁移。目前的工作使用的语义信息包括:特征These attributes can be semantic (“spotty”) or discriminative (“dogs have it but sheep do not”) ,词向量。 传统的ZSL通常学习一个universal视觉-语义变换,然后对目标类直接应用。这使得视觉样本和类别语义被映射在同一个空间中,ZSL由最邻近算法完成。 这篇工作研究genralized ZSL问题,即部分测试样本会来自源类别,现有工作的问题是对源类别的过拟合。
ZSL最大的难点在于没有任何目标类别的样本,一个最直接的思路是利用与目标类别相似的源类别的样本来进行训练。比如我们可以用horse的样本来训练一个zebra的分类器。
这篇工作的贡献分为两点:1. 新的transeferable contrasive network for GZSL. 2.discriminative property和transeferable property(其实就是两种损失). 总体上这篇工作的方法比较直接经典,所以对我们了解ZSL领域会更有帮助一些。 ## Related work ### Semantic Information 零样本的知识迁移完全是依靠语义信息完成的,语义信息建立了不同类别的联系,比如zebra是有黑白斑纹的马,horse则是纯色的马,这种语义信息非常直接地描述两个类别的联系和差别。attibute和word vector是最常见的语义信息,attribute描述了一个物体(是否有生命,具体的颜色,形状)但是需要专家信息;wordvector则是直接从语料库中无监督抽取的,这会带来噪声。这篇工作用的是attributes。 ### Visual-Sematntic Transformations Visual to semantic embeddings. 这类方法把视觉的表示转换为语义的表示,然后在语义空间上做图像的识别,比如判别这个图像中物体的形状、颜色等等,然后去语义空间匹配具体的类别。具体的工作就不介绍。 Semantic to visual embeddings. 这类方法与上面的方法正好相反。上面这种方法会造成一个叫hubness的问题: 在进行语义匹配时使用的是KNN,某几个vector成为大多数vector的近邻点。一个典型的方法是通过语义信息学习一个视觉空间上的目标类原型,有的还利用GAN去生成目标类的样本,然后直接训练目标类分类器。 
Latent space embedding. 这类方法直接把视觉空间和语义空间进行再编码,在一个latent space进行图像识别。在这类方法中,识别变成了语义表示和视觉表示的相似度匹配,一些度量学习的方法也被引入了。这篇工作就是这个类别的。 ### Zero-Shot Recognition 这是ZSL的最后一步,大概分为两种:1.用最邻近方法来识别出目标类别的样本2.训练分类器来识别具体属于哪个目标类。 ## Approach 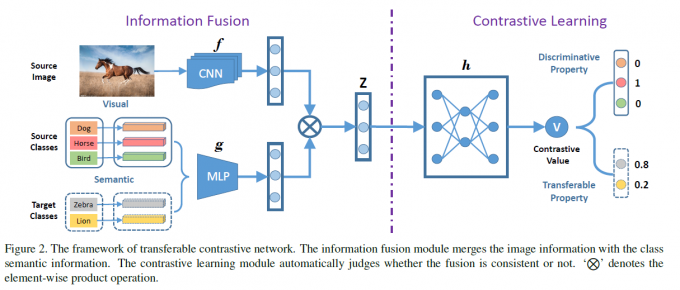
即学习如何对比图片和类别的语义,上图显示了大致过程。 ### 问题设定 给定K个源类别和L个目标类别,源类别和目标类别不重叠。源类别包含N个有标签图像。为了建立源类别和目标类别的关系,提供了K+L个类别语义。ZSL目标是训练一个目标类别的分类器,GZSL是训练源类别和目标类别的分类器。 ### Contrasive Network 1.Information Fusion. 这部分就是编码后逐元素相乘 2.Contrasive Learning. 之前的工作是使用固定距离,比如L2和余弦距离来计算图片和类别的相似性。令表示图片i和类别j的对比值,这由一个神经网络来决定。利用源类别的标签就可以得到下面一项损失: \[ \begin{aligned}L_D=-\Sigma_{i=1}^N\Sigma_{j=1}^Km_{ij}\log v_{ij}+(1-m_{ij})log(1-v_{ij})\end{aligned} \] 关键在于第二个损失,即让模型能够将源类别知识迁移到目标类别的一项。这由类别间的相似性完成,令表示源类别k和目标类别j的相似性,我们可以得到如下的损失: \[ \begin{aligned} L_T=-\Sigma_{i=1}^N\Sigma_{j=K+1}^{K+L}s_{y_ij}\log v_{ij}+(1-s_{y_ij})log(1-v_{ij}) \end{aligned} \] 即查看样本i的类别,计算i类别与每个target类别的相似性,生成一个伪标签给样本i和对应的目标类别。其实比较naive. 最终的损失是两者的带权和. 3.Class Similarity.类别间的相似度是由下面的优化来计算的,而不是直接用L2或者余弦距离: \[ \begin{aligned} \mathbf{s}_k=\arg\min_{\mathbf{s}_k}||a_k-\Sigma_{j=K+1}^{K+L}a_js_{kj}||_2^2+\beta||\mathbf{s}_k||_2 \end{aligned} \] 即用目标类的特征重构源类别,重构系数就是相似性。得到系数后会进行归一化。
Zero-Shot Recoginition
进行分类时,只要查看最大的那个类即可。我很怀疑做GSL时能不能分类到目标类上,因为源类别提供的都是0-1标签(比较自信),而目标类则是一些中间值(比较保守)。 ## 实验 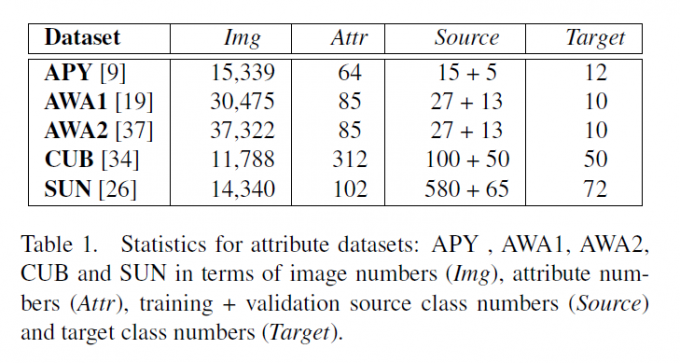
这些数据集看起来还是比较复杂,以下是SUN和CUB数据集的示例:


ts是目标类别top1精度,tr是源类别top1精度。在GSL上这篇工作对于目标类别的性能提升很明显,所以调和平均H的指标也更好。 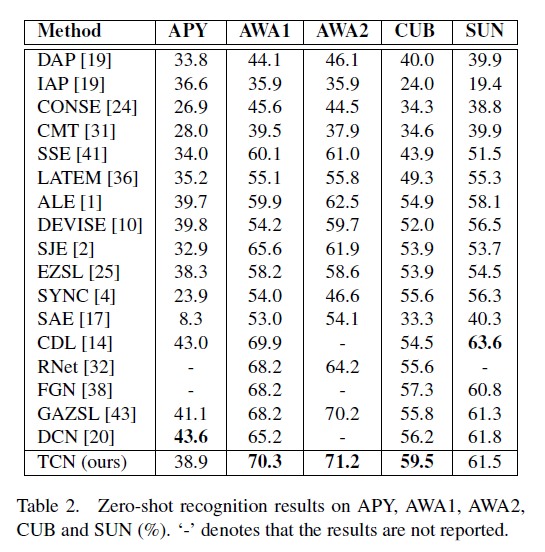
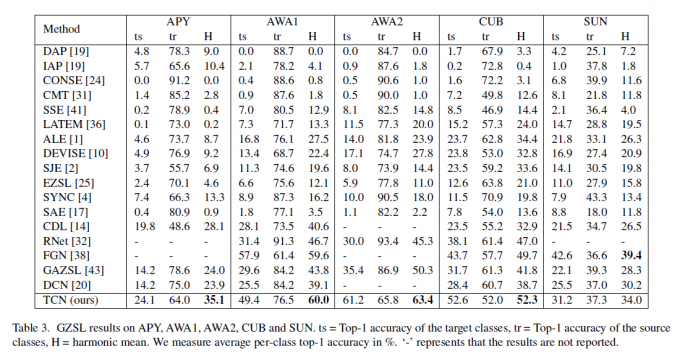
这张表格对比损失被移除的baseline,这项损失在ZSL上影响并不大,但是在GSL上的作用很明显。 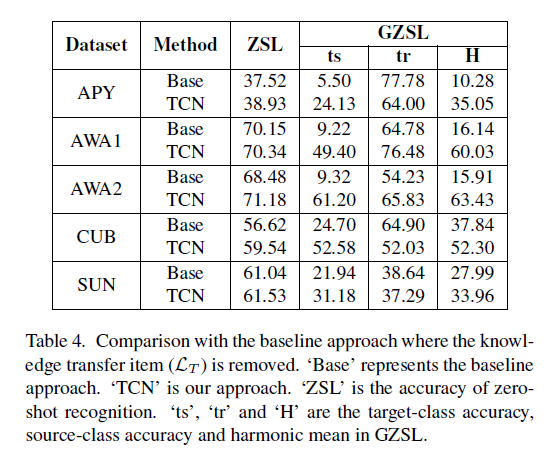
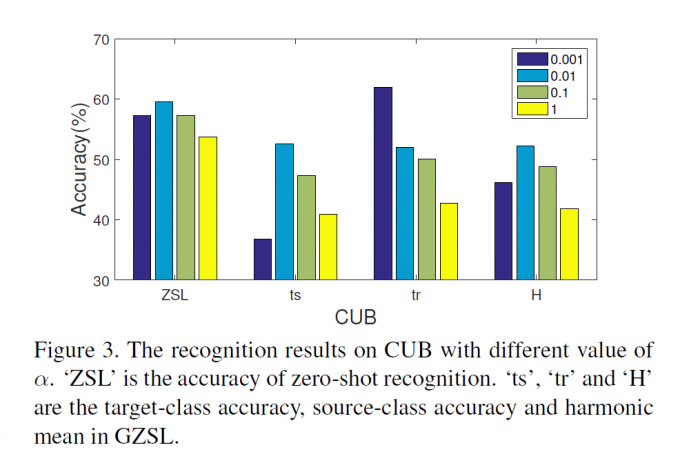
作者调整transeferable箱的权重,0.001时在source上表现很好,target上表现很差,0.01时两个都差不多。之后再增加不会使性能提升。
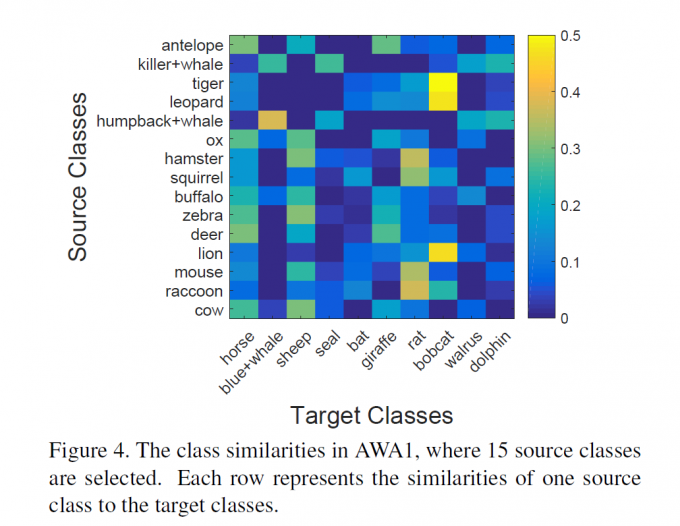

leopard和bobcat在语义上是相似的,而leopard是有对应样本的。类似的pair可以找到很多,比如killer whale和blue whale. 对于APY数据集这种粗粒度的数据集,这种相似性是十分粗略的,造成了ZSL性能不够理想。比如building和train的相似性非常高。  未见过的类别确实被准确分类了,没有像想象中那样都被分到已有类别中。
未见过的类别确实被准确分类了,没有像想象中那样都被分到已有类别中。
总结
没有免费的午餐,机器学习离开了数据和标注是无法工作的。ZSL没有目标类别的任何样本,所以需要语义信息作为数据的替代,然后通过某种方式产生标签。在ZSL的框架下,分类任务变成了语义空间和视觉空间的匹配,这是一个很有意思的角度。ZSL研究了一种更general的知识迁移,即图像和文本之间的迁移,我认为还是很有前景的,CV和NLP在未来肯定会走向深度交叉乃至合并的。