Figure 1
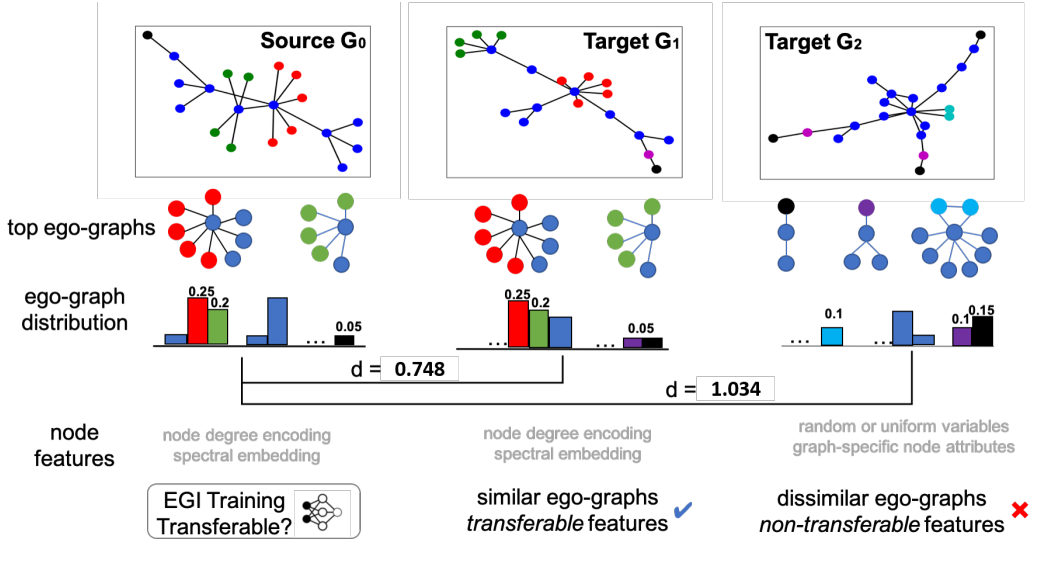
最近一些工作研究了GNN的预训练,但是关于GNN的可迁移性并没有理论根据。这篇文章建立了一个有理论保证的图神经网络迁移学习框架。框架包含两个部分,第一是Ego-graph information maximization(EGI)的迁移方法,第二是当节点特征是结构相关时分析了EGI的可迁移性。
最近一些工作研究了GNN的预训练,但是关于GNN的可迁移性并没有理论根据。这篇文章建立了一个有理论保证的图神经网络迁移学习框架。框架包含两个部分,第一是Ego-graph information maximization(EGI)的迁移方法,第二是当节点特征是结构相关时分析了EGI的可迁移性。
这篇文章大部分理论贡献都来自其它文章,刻画了目前GNN对于同构判定的能力边界,总结得很好可以当综述看。这篇文章还提出了一个改进模型,能够在保持scalability的同时,在理论和实践上都更加优越:原文链接。
对于矩阵函数,我们也有对应的求导法则,这些法则对于矩阵的优化是必要的,掌握它们便于我们进行实际应用中的数值分析。对于\(n\times n\)矩阵,以及\(n\times 1\)的向量:
最近想搞一篇关于自监督图学习的工作,之前博客有一篇基于Transformer的。但这个工作太暴力了,效果也非常的好,比肯定很难比得过,所以不可能再去做这个领域(好在它只是做分子数据的)。
与半监督图像学习、小样本学习等领域不同的是,零样本学习开始引入一些语义信息,可以理解为同时利用图像与文本信息。在前言部分,我们从零样本学习的定义(what)、具体的用途(why)、以及实际方法(how)来简要介绍该研究领域。此外,我们详细地介绍了一篇CVPR2019广义零样本学习的代表工作。
研究分子的表示学习,最近的工作直接使用GNN来进行。然而有两点问题:1.分子标注量不够2.对新合成分子泛化性不够。这篇工作提出了GROVER,graph representation from self-supervised message passing transformer. GROVER设计了node/edge/graph层级的自监督任务,并将message passing network与transformer融合,获得更好的分子编码。GROVER含有一亿参数在千万分子上进行无监督训练,在11个benchmark上达到了平均6%的精度提升。
The convex condition of the objective function guarantees extrema uniqueness. It says that if \(f\) is convex, we can discuss the convergence rate of optimization methods by estimating \(||f(w_t)-f^{opt}||\), where \(f^{opt}\) is the global maximum/minimum (optimum). Otherwise, we know nothing about the distance and only discuss \(\min_{t\in\{0,1,\dots,T\}}||\nabla f(w^t)||^{2}\).
尽管嵌入模型很明显是基于分布假设来进行优化,使常出现的word-context对向量内积极大化,并极小化随机word-context对内积。但对于这些优化指标的讨论很少,也不清楚为什么这样能够得到期望的结果。这篇文章对此进行了探讨,表明SGNS(skip-gram with negative-sampling)的训练方法实际上是加权矩阵分解,其目标函数在隐式地分解一个移动PMI矩阵,并基于此提出了更高效的优化方式。
本工作由keith等(google)完成发表在2016年nips上。对于联邦学习,隐私性与安全性是首要的,为此可以接受模型性能的轻微下降。Secure Aggregation(以下简称SA)是一类从分布式群体\(u \in \mathcal{U}\)中获取统计量而不泄露单用户信息\(x_{u}\)的方法。在这篇文章中,作者提出了用于保护联邦学习中分布式梯度更新的单个用户梯度的协议,这项协议在效率以及稳定性上都做了考虑,在至多三分之一用户未完成协议时仍然能保证安全性。
“夕阳余晖,淡淡霞光中的红蜻蜓。
童年见到你,那是哪一天?”
人们在我的世界之外喧嚣着,我仍然在深夜的路上,唱着红蜻蜓。
临近毕业,这寂静仿佛延伸了,变成了某种更为深刻的符号,从1998年开始,便代表着我的人生。